No — Databricks is a data lakehouse platform built for analytics and AI/ML workloads, not a customer data platform (CDP). A cloud data warehouse or lakehouse stores and processes data for analysis. A CDP unifies customer identities, activates profiles across channels in real time, and closes the feedback loop so AI can learn from outcomes. Databricks helps you build models on customer data; a CDP helps you act on those models and improve them continuously.
This guide covers what Databricks does well, where it stops short of CDP functionality, and how to decide whether your organization needs one, the other, or both.
What Databricks Does Well for Customer Data
Databricks has genuine strengths that make it a popular foundation for customer data initiatives:
- Unified analytics and ML: Databricks combines data engineering, data science, and machine learning on a single platform. For building churn models, recommendation engines, or propensity scores, the notebook-to-production workflow is among the strongest available
- Lakehouse architecture: Delta Lake merges the flexibility of data lakes (unstructured data, schema evolution) with the reliability of data warehouses (ACID transactions, time travel). This is particularly valuable for customer data that arrives in varied formats — clickstream JSON, CRM exports, IoT telemetry
- Data governance: Unity Catalog provides unified access control, audit logging, lineage tracking, and data discovery across all data assets. For organizations managing customer PII across teams and regions, Unity Catalog offers enterprise-grade governance
- Zero-copy data sharing: Delta Sharing enables cross-organization data exchange without copying the underlying data. This is a genuine architectural advantage for privacy-conscious customer data collaboration
- Natural language querying: Databricks Genie and the AI/BI product let business users query data conversationally, democratizing access to customer insights without requiring SQL expertise
- Feature serving: Databricks Feature Store and Feature Serving endpoints enable low-latency feature retrieval for real-time ML inference, bridging the gap between batch model training and operational serving
- Agentic AI capabilities: The Mosaic AI Agent Framework enables developers to build AI agents that query Unity Catalog, invoke MLflow models, and orchestrate multi-step workflows — bringing agentic capabilities to the lakehouse for use cases where the agent’s primary data source is the lakehouse itself
- Open-source ecosystem: Spark, MLflow, Delta Lake — Databricks builds on open standards, reducing vendor lock-in concerns that arise with proprietary platforms
For organizations whose primary need is data science, ML model development, and large-scale analytics, Databricks is a strong foundation.
Databricks and the Customer Intelligence Loop
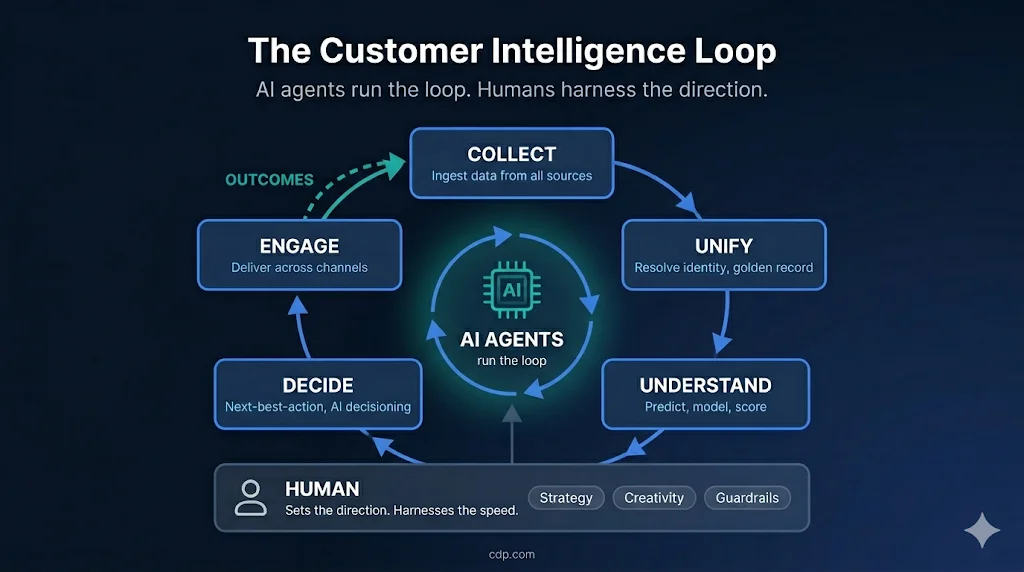
The Customer Intelligence Loop — COLLECT → UNIFY → UNDERSTAND → DECIDE → ENGAGE → back to COLLECT — is the continuous cycle through which organizations turn raw customer data into action and learning. AI agents run the loop continuously; humans harness the direction with strategy, creativity, and guardrails. Mapping Databricks’ capabilities to each stage reveals where the lakehouse excels — and where the loop slows down without a CDP:
| Loop stage | Databricks’ role | What a CDP adds |
|---|---|---|
| COLLECT | Strong — Delta Lake Autoloader ingests streaming and batch data from any source | Real-time event streaming with immediate profile updates |
| UNIFY | Batch — Spark jobs and SQL joins on deterministic keys; no native probabilistic matching | Real-time probabilistic identity resolution that stitches anonymous and known profiles as events arrive |
| UNDERSTAND | Very strong — Mosaic AI, MLflow, and custom Spark for churn, LTV, recommendations, and customer embeddings | Native predictive scoring, or imports lakehouse-trained models |
| DECIDE | Limited — MLflow model serving can power real-time inference, but orchestrating decisioning across profiles at activation time requires operational infrastructure the lakehouse does not natively provide | Sub-50ms AI decisioning on unified profiles |
| ENGAGE | None — requires external messaging platform connected via reverse ETL | Native email, SMS, push notification delivery |
| Loop closure | Open — outcomes return via batch ingestion (hours to days). Delta Sharing can accelerate reads between analytical systems, but engagement outcomes from external ESPs still flow back via batch ETL | Closed — outcomes update profiles and models within seconds |
Databricks’ strength in UNDERSTAND is a genuine differentiator — the notebook-to-MLflow-to-production pipeline for customer ML models is among the strongest available. A CDP completes the operational half of the loop (DECIDE, ENGAGE) and closes it so those models can learn from outcomes in real time, not on next-day batch cycles. The two platforms are complementary: Databricks trains the intelligence, the CDP acts on it and learns.
Not every organization needs every stage to operate in real time. For batch use cases — churn models retrained daily, recommendation engines updated hourly, quarterly segmentation reviews — Databricks covers the loop stages that matter, and activation runs on comfortable batch cycles. The real-time loop becomes important when use cases shift to triggered messaging, in-session personalization, or AI agents that need to learn from outcomes in seconds. For the complete framework, see Customer 360 in the AI Era.
Five CDP Capabilities Databricks Does Not Provide
The loop stages where Databricks stops short translate into five specific capability gaps. Despite its breadth, Databricks was not designed for the operational workloads that define a CDP:
| Capability | What a CDP provides | What Databricks offers |
|---|---|---|
| Native messaging | Built-in email, SMS, and push notification delivery | None — requires a separate ESP connected via reverse ETL |
| Real-time profile serving | Sub-50ms API lookups for in-session personalization | Lakehouse query latency ranges from hundreds of milliseconds to seconds. Feature Serving endpoints can deliver low-latency reads for individual features, but the platform is optimized for analytical workloads, not high-concurrency operational profile access |
| Automated identity stitching | ML-powered identity resolution that merges anonymous and known profiles as events arrive | Requires custom Spark jobs or a third-party identity tool; no native probabilistic identity matching |
| Customer Intelligence Loop | COLLECT → UNIFY → UNDERSTAND → DECIDE → ENGAGE in seconds within one platform | Stages split across notebooks/pipelines and external tools. Outcome data returns via batch ingestion |
| Marketer self-service | Visual segmentation UI, drag-and-drop journey builder | Designed for data engineers and data scientists, not marketing operators |
These are not roadmap items — they reflect the fundamental difference between an analytical platform (optimized for processing and modeling data) and an operational platform (optimized for real-time customer engagement).
The Composable Approach: Databricks + Activation Partners
Databricks actively promotes a composable CDP approach through its partner ecosystem. A typical Databricks-based composable architecture includes:
- Databricks — lakehouse storage and compute (system of record)
- Reverse ETL tool — syncs audiences to marketing and advertising platforms
- Identity resolution tool — deterministic and probabilistic matching (some integrate natively via Delta Sharing)
- Messaging platform — email, push, SMS delivery
- Orchestration — Databricks Workflows or pipeline scheduling tools
Databricks positions this as best-of-breed: each component excels at its specialty, and the lakehouse provides the unifying data layer. This is architecturally coherent. But the same structural trade-offs apply as with any composable stack. For a side-by-side comparison of the vendors that provide these activation layers, see the composable CDP vendors comparison.
Delta Sharing: Zero-Copy with Limits
Delta Sharing is one of Databricks’ strongest differentiators. It enables other platforms to read lakehouse data without copying it — a genuine improvement over traditional ETL-based integration. However, “zero-copy read” is not the same as “zero-copy activation”:
- When a reverse ETL tool syncs an audience from Databricks to a messaging platform, the audience data (including PII) is copied to the destination’s infrastructure for message delivery. This is how reverse ETL works — the activation step inherently creates copies
- Each downstream tool that receives synced data creates another PII boundary. A typical composable stack duplicates customer data across 4–6 vendor systems despite Delta Sharing’s zero-copy reads at the warehouse layer
Delta Sharing reduces copies between analytical systems. It does not eliminate copies to operational systems. The distinction matters for CISOs evaluating data residency and breach notification obligations.
Total Cost of Ownership
A representative 3-year cost structure for a Databricks-based composable CDP (~5M profiles, 10 destinations):
| Cost component | Annual estimate |
|---|---|
| Databricks compute (identity + segmentation workloads) | $100K–$250K |
| Identity resolution tool | $50K–$150K |
| Reverse ETL platform | $30K–$100K |
| Messaging platform (ESP) | $50K–$150K |
| Data engineering FTEs (3–5 dedicated) | $450K–$1M |
| Total annual | $680K–$1.65M |
An Agentic CDP that bundles identity resolution, AI decisioning, and native messaging into a single platform typically delivers comparable or lower 3-year TCO — with the added advantage of closed-loop AI learning and fewer vendor relationships to manage. Note that both architectures carry operational headcount costs beyond data engineering: composable stacks require pipeline maintenance and vendor coordination, while CDPs require campaign operations and platform administration. The FTE estimates above reflect data engineering effort dedicated to CDP-specific workflows; in practice, these engineers often support broader data initiatives as well. For a detailed cost analysis, see 5 Questions Data Engineers Should Ask About Composable CDPs.
On-Call Burden
A Databricks composable stack introduces 4–5 distinct failure points in the activation path: Databricks job failure, Delta Sharing permission error, reverse ETL sync timeout, identity resolution mismatch, messaging delivery issue. When an audience sync fails at 2am, the root cause could span any of these vendor boundaries. Mean time to resolution is structurally higher than a single-platform CDP where the entire pipeline — from data ingestion to message delivery — is observable in one monitoring console.
When Databricks Alone Is Enough
Not every organization needs a CDP. Databricks alone is likely sufficient if:
- ML is your primary customer data use case: Building churn models, recommendation engines, propensity scores, and customer embeddings. If the output is a model or a batch prediction table — not a triggered message — Databricks is purpose-built for this work. The notebook-to-MLflow-to-production pipeline is one of Databricks’ strongest differentiators, and no CDP replicates it
- Your team is engineering-led: Data scientists and engineers drive customer analytics. Marketing consumes insights via dashboards and reports, not self-service segmentation. Databricks’ notebook environment and Spark-native workflows give ML teams more flexibility than any CDP’s built-in ML
- Activation is batch and infrequent: Weekly audience pushes to 2–3 ad platforms. The composable overhead is manageable at low sync frequency and destination count
- You need cross-organizational data collaboration: Delta Sharing enables zero-copy data exchange with partners, agencies, and clean room providers — a capability most CDPs do not offer. If your customer data strategy depends on second-party data partnerships, Databricks provides the collaboration layer natively
- You already have a messaging platform: If your existing messaging platform is handling email, push, and SMS and you’re satisfied with the batch latency of reverse ETL syncs, Databricks as the analytical backbone may be sufficient
When to Add a CDP to Databricks
The inflection point arrives when the organization needs real-time operational capabilities, not just analytical insight:
- Real-time activation: Cart abandonment, in-session recommendations, event-triggered welcome series — these require sub-second profile lookups and immediate message delivery that lakehouse query latency cannot support
- Native messaging: Managing a separate messaging platform means managing a separate vendor, a separate PII boundary, and a separate deliverability stack. A CDP with built-in email, SMS, and push eliminates the reverse ETL sync between decisioning and delivery — the message sends from the same platform that decided to send it
- Marketing self-service: Marketers want to create segments, design journeys, and launch campaigns without writing Spark jobs or SQL. A CDP provides the visual layer that unlocks marketing velocity
- Closed-loop AI: When AI agents need to observe customer behavior, decide the next action, execute it, and learn from the outcome in seconds — the feedback loop must close within a single system. A composable stack splits this loop across 3–5 vendors, introducing hours of latency in the learning step
- Compliance simplification: Consolidating activation into a CDP with native messaging reduces PII boundaries from 5+ vendor systems to 1–2, simplifying SOC 2 audits and GDPR breach notification
Practical example: A financial services company using Databricks builds a churn propensity model in a notebook using MLflow. The model scores well — AUC 0.87 — and the team deploys it as a scheduled Databricks Workflow that scores all customers nightly. The scores are synced via reverse ETL to a messaging platform, which triggers a retention email to high-risk customers. The problem: a customer’s churn risk spikes at 2pm after a failed transaction, but the model won’t re-score until midnight, the sync won’t push until 6am, and the retention email arrives at 9am — 19 hours after the triggering event. On an Agentic CDP, the failed transaction updates the customer’s profile in real time, the AI model re-evaluates risk immediately, and a retention message is sent within minutes — while the customer is still reachable.
The Migration Path
Adding a CDP does not require abandoning Databricks. The two work well together:
- Phase 1: Connect the CDP to Databricks via Delta Sharing or direct connector. Continue using Databricks for batch ML models (churn, LTV). CDP handles real-time identity and activation
- Phase 2: Route real-time event streams (web, mobile, transactional) through the CDP. Databricks continues to receive these events for analytical workloads via the CDP’s warehouse sync
- Phase 3: Consolidate messaging in the CDP’s native channels. Retire the reverse ETL + ESP stack as contracts renew. Databricks remains the ML and analytics backbone
This hybrid architecture plays to each platform’s strengths: Databricks for deep analytics and model training, CDP for real-time activation and closed-loop AI.
FAQ
Can Databricks replace a CDP?
No — Databricks and CDPs serve different architectural purposes. Databricks excels at data engineering, ML model training, and large-scale analytics on a lakehouse architecture. A CDP excels at real-time identity resolution, multi-channel activation, and closed-loop AI decisioning. Organizations focused on data science and batch analytics may find Databricks sufficient. Organizations that need real-time personalization, native messaging, or marketing self-service need a CDP — alongside their lakehouse, not instead of it.
Do you need a CDP if you have Databricks?
It depends on whether you need to act on customer data in real time — and whether you want native messaging in the same platform. If your primary use cases are batch ML models, cohort analytics, and data team-driven reporting, Databricks is a strong standalone platform. If you need real-time triggered messaging, native email/SMS/push delivery without a separate ESP, marketer-accessible segmentation, or AI agents that learn from campaign outcomes in seconds, a CDP adds the operational layer that Databricks architecturally cannot provide. Most mid-to-large enterprises benefit from using both.
What is the difference between a data lakehouse and a CDP?
A data lakehouse is an analytical platform; a CDP is an operational platform. A lakehouse like Databricks combines data lake flexibility with warehouse reliability — it stores, processes, and models data at scale. A CDP unifies customer identities, segments audiences, sends messages across channels, and runs real-time AI decisioning. The lakehouse answers “what happened?” and “what might happen?” A CDP answers “what should we do right now?” and learns from the result.
