Customer 360 AI is the evolution from static unified profiles to dynamic, AI-driven customer views that autonomously decide, act, and learn across channels in real time. Where first-generation customer 360 focused on assembling a single view of the customer, the AI era demands that the profile itself becomes an operational asset — not just something humans query, but something AI agents access to drive personalized interactions at scale.
This shift is forcing organizations to rethink the architecture behind their customer 360. Cloud data warehouses like Snowflake and Databricks have become popular foundations for unifying customer data. But unification is only part of the problem. What happens after the profile is built — how the organization acts on it and learns from outcomes — is where architectural choices diverge.
What Is Customer 360 AI?
A traditional customer 360 consolidates data from CRM, email, web, mobile, POS, and support into a single profile. It answers: Who is this customer? What have they done?
Customer 360 AI extends this by adding predictive intelligence and operational activation. It answers: What should we do next? Did it work? How do we improve?
The difference is not incremental — it requires fundamentally different architecture. A read-optimized analytical store (the data warehouse) serves the first question. An operational platform with real-time identity resolution, native messaging, and AI decisioning serves the second.
Three Forces Reshaping Customer 360 — and the Missing Fourth
Snowflake’s AI Era Playbook (Florian Delval, 2025) identifies three forces reshaping customer 360: data gravity, privacy, and predictive profiles. These are real and well-observed. But the framework stops short of the most consequential shift.
Data Gravity
Customer data is consolidating into cloud data platforms. As data mass increases, applications and processing gravity toward the data — not the other way around. This is why cloud data warehouses have become central to customer data strategies: it is more efficient to compute where the data lives than to move data to where the computation runs.
This force is genuine. CDPs that ignore data gravity — forcing organizations to replicate all data into a proprietary store — create unnecessary duplication. Modern hybrid CDPs address this by connecting to external warehouses while maintaining a real-time cache for operational access.
Privacy and Governance
Regulatory pressure (GDPR, CCPA, emerging state-level laws) demands that organizations minimize unnecessary data movement and maintain auditable access controls. Cloud data warehouses with mature governance frameworks — role-based access, column-level masking, audit logging — provide a strong compliance foundation.
This force is also genuine. However, the privacy argument cuts both ways. Composable CDP architectures that rely on reverse ETL to activate data create PII copies in every downstream tool. The more channels and destinations you activate, the more copies you create — and the more complex your breach notification and data residency obligations become.
Predictive Profiles
Static demographic profiles are evolving into dynamic, ML-enriched views that include behavioral scores (engagement propensity), predicted outcomes (churn risk, LTV), and real-time context (current session activity, recent interactions). Cloud data warehouses with native ML capabilities (Snowflake Cortex, Databricks Mosaic AI) can build these enrichments at scale.
This force is genuine for batch prediction use cases: churn scoring, lifetime value modeling, demand forecasting. These models retrain well on daily or hourly batch cycles and do not require real-time feedback.
The Fourth Force: Act and Learn
The three forces above address how customer 360 data is stored, governed, and enriched. They do not address how it is activated and how the system learns from outcomes.
This is the gap. In the AI era, the value of a customer 360 is not in the profile itself — it is in the Customer Intelligence Loop that the profile enables. To understand where that loop slows down, it helps to map the full cycle.
The Customer Intelligence Loop
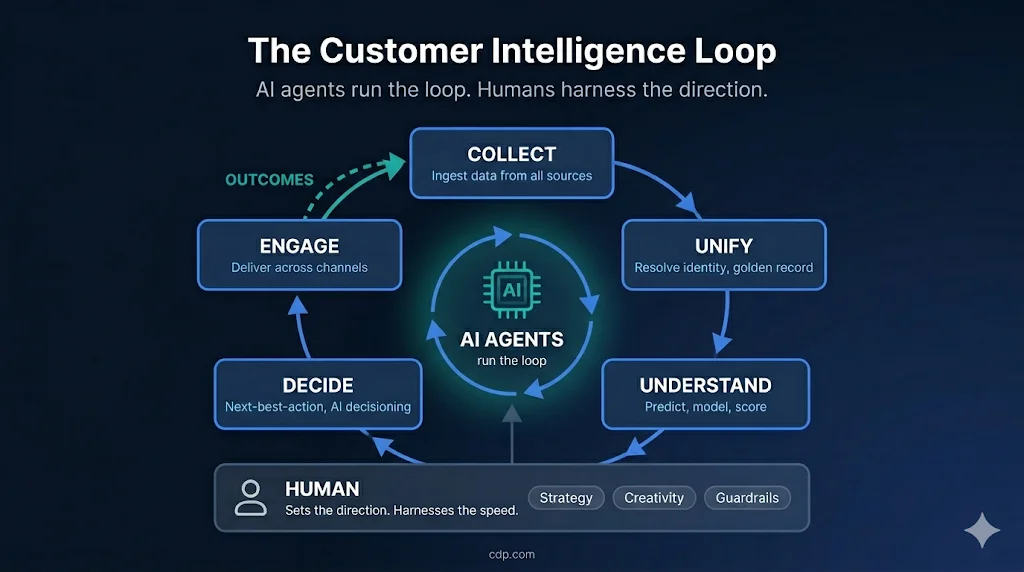
The Customer Intelligence Loop — COLLECT → UNIFY → UNDERSTAND → DECIDE → ENGAGE → back to COLLECT — is the continuous cycle through which organizations turn raw customer data into action and learning. AI agents run the loop continuously; humans harness the direction with strategy, creativity, and guardrails. Each stage builds on the previous:
- COLLECT — Ingest customer events from every touchpoint: web, mobile, POS, CRM, support, IoT
- UNIFY — Resolve identities and merge records into a single customer profile
- UNDERSTAND — Enrich profiles with predictive scores, segments, and behavioral context
- DECIDE — AI determines the next-best action for each individual in real time
- ENGAGE — Execute that action: send a message, adjust an offer, personalize a page
The loop closes when engagement outcomes (opens, clicks, purchases, ignores) flow back to COLLECT — updating the profile and improving the next decision. This is what researchers call a continuous intelligence system: not a batch pipeline that runs weekly, but a cycle that completes in seconds. It is also why Tomasz Tunguz argues in AI’s Bundling Moment that AI rewards platform breadth over best-of-breed specialization — splitting the loop across vendors introduces latency and context loss that undermines AI effectiveness.
Cloud data warehouses and CDPs each excel at different stages of this loop — and understanding that division is the key to choosing the right architecture.
The Customer Intelligence Loop: CDW vs CDP
| Loop stage | Cloud data warehouse role | CDP role |
|---|---|---|
| COLLECT | Strong — Snowpipe Streaming, Delta Lake Autoloader ingest high-volume events | Strong — real-time event streaming with immediate profile updates |
| UNIFY | Batch — SQL/dbt joins on deterministic keys (email, account ID) | Real-time — probabilistic identity resolution that stitches anonymous and known profiles as events arrive |
| UNDERSTAND | Strong — Cortex, Mosaic AI, custom Spark for churn, LTV, and recommendation models | Supported — native predictive scoring, or imports warehouse-trained models |
| DECIDE | Limited — analytical query latency (seconds) is too slow for in-session decisioning | Strong — sub-50ms AI decisioning on unified profiles |
| ENGAGE | None — requires external messaging platform connected via reverse ETL | Native — built-in email, SMS, push notification delivery |
| Loop closure | Open — outcomes return via batch ETL (hours to days) | Closed — outcomes update profiles and models within seconds |
The pattern is clear. Cloud data warehouses own the analytical stages: COLLECT (high-volume ingestion), UNIFY (batch identity), and UNDERSTAND (ML model training). CDPs own the operational stages: DECIDE (real-time AI) and ENGAGE (native messaging). The critical differentiator is loop closure — feeding engagement outcomes back to COLLECT fast enough for AI to learn and improve the next decision.
A composable stack that splits DECIDE and ENGAGE across 3–5 vendors keeps the loop structurally open. An Agentic CDP closes it by executing DECIDE, ENGAGE, and loop closure within a single platform boundary. The warehouse remains the analytical backbone — both systems are necessary to run the full loop.
This matters because AI agents that cannot learn from outcomes in real time are structurally limited. They can make predictions, but they cannot improve those predictions based on what actually happened. Each interaction that goes unlearned is a missed optimization. Over weeks and months, closed-loop systems accumulate compounding advantages in personalization accuracy, offer relevance, and campaign conversion.
When Real-Time Matters and When It Doesn’t
Not all customer 360 use cases require real-time capabilities. The architectural choice depends on which tier your use cases fall into.
Real-Time Required
These use cases need sub-second profile access, immediate action, and fast learning:
- Cart abandonment: Detecting abandonment, deciding the offer, and sending the message must happen within minutes — not hours. Each hour of delay reduces recovery rate by an estimated 10–15%
- In-session personalization: Product recommendations, content customization, and dynamic offers based on the customer’s current browsing context. Warehouse query latency (seconds) cannot support page-load-time decisions (milliseconds)
- Event-triggered messaging: Welcome series after signup, re-engagement after inactivity, post-purchase follow-up. The customer expects immediacy — a “welcome” email arriving 24 hours after registration loses its impact
- AI agent interactions: When AI agents serve customers in real time — chat, voice, or autonomous outreach — they need instant access to the full customer profile. Querying a warehouse per interaction is architecturally impractical
Business impact: A mid-market retailer implementing cart abandonment on a composable stack (cloud data warehouse + reverse ETL + messaging platform) required three teams and two weeks to ship the campaign. The same campaign on an Agentic CDP was live in under an hour — configured by a marketing manager without engineering involvement.
Batch Is Fine
These use cases work well with daily or hourly data refreshes:
- Churn prediction and prevention: Monthly churn models retrained on daily data are standard practice. The intervention (email series, offer) is planned, not triggered in the moment
- Lifetime value forecasting: LTV models inform strategic decisions (segment investment, acquisition budgets) that operate on weekly or monthly cycles
- Recommendation model training: Collaborative filtering and content-based models retrain on batch data. The trained model may serve real-time predictions, but the training itself is batch
- Cohort analysis and reporting: Historical segmentation, funnel analysis, and attribution reporting are inherently retrospective
For these use cases, a cloud data warehouse with native ML capabilities is the right tool. There is no architectural advantage to running batch predictions through a CDP.
Total Cost of Ownership: CDW Stack vs Agentic CDP
Cost is frequently the deciding factor. A representative comparison for a mid-market organization (~5M profiles, 10 activation destinations, 3-year horizon):
The CDW + Reverse ETL + ESP Stack
| Component | Annual cost |
|---|---|
| Cloud data warehouse compute | $80K–$250K |
| Reverse ETL platform | $30K–$100K |
| Messaging platform (ESP) | $50K–$150K |
| Identity resolution (if separate) | $50K–$150K |
| Data engineering FTEs (3–5 dedicated) | $450K–$1M |
| Integration maintenance | $20K–$50K |
| Annual total | $680K–$1.7M |
Agentic CDP
| Component | Annual cost |
|---|---|
| Platform license (bundled: identity, AI, messaging, activation) | $200K–$500K |
| Data engineering support (0.5 FTE for integration) | $75K–$150K |
| Cloud data warehouse (retained for analytics) | $50K–$150K |
| Annual total | $325K–$800K |
The CDW stack often appears cheaper at entry — the warehouse is already paid for, and reverse ETL tools have low starting prices. But per-row pricing, connector costs, and engineering headcount scale non-linearly. By year 3, the TCO of a multi-vendor composable stack frequently exceeds an Agentic CDP with bundled capabilities. The difference widens as activation volume (more channels, higher sync frequency) increases.
The On-Call Reality
Beyond licensing costs, consider operational burden. A composable stack introduces 4–5 distinct failure points: warehouse job timeout, reverse ETL API rate limit, identity resolution mismatch, ESP delivery failure, orchestration DAG error. When a sync breaks at 2am, the root cause could span any vendor boundary. A single-platform CDP consolidates monitoring, alerting, and troubleshooting into one system with one support contract.
What Cloud Data Warehouse Vendors Are Building
Snowflake and Databricks are actively extending their platforms toward operational use cases. These capabilities are worth understanding:
- Snowflake Cortex: LLM-powered analysis, natural language querying, ML model training within the warehouse
- Dynamic Tables: Continuous, incremental data transformation — moving Snowflake closer to near-real-time processing
- Databricks Genie: Conversational interface for business users to query lakehouse data
- Delta Sharing: Zero-copy data sharing across platforms and organizations
These are meaningful capabilities that strengthen the analytical layer. However, they do not add native messaging, sub-second profile serving, or closed feedback loops — the operational capabilities that define a CDP. Extending a warehouse into an operational platform is architecturally equivalent to building a CDP inside the warehouse rather than replacing one.
For detailed analysis of Snowflake and Databricks as CDP alternatives, see Is Snowflake a CDP? and What Is Databricks CustomerLake?.
Migration Path: CDW First, CDP for Real-Time Action
Most organizations do not need to choose one architecture over the other. The migration typically follows three phases:
- Phase 1 — Analytical foundation: Use your cloud data warehouse for customer data unification, batch ML models, and reporting. This is where most organizations start, and it delivers immediate value for analytics use cases
- Phase 2 — Add real-time action: When real-time use cases emerge (triggered messaging, in-session personalization, AI agents), add an Agentic CDP connected to the warehouse. The CDP handles real-time identity, activation, and feedback loops. The warehouse remains the analytical backbone
- Phase 3 — Consolidate activation: As the CDP proves value, consolidate messaging and activation into the CDP’s native channels. Retire the reverse ETL + ESP stack as contracts renew. The warehouse continues to serve batch analytics and ML model training
This phased approach preserves existing data infrastructure investments, minimizes disruption, and incrementally adds the real-time operational capabilities that the AI era demands.
Quick Self-Assessment: Do You Need a CDP?
Answer these five questions to determine where your organization sits:
- How many real-time use cases do you have today? If none — stay with your warehouse. If 3+ — evaluate a CDP
- How many vendor systems hold customer PII? Count every tool that receives customer data via reverse ETL. If 5+ — the compliance argument for consolidation is strong
- How long does it take to ship a triggered campaign? If the answer is “weeks” and involves data engineering tickets — a CDP’s self-service layer will accelerate marketing
- Do your AI models learn from campaign outcomes in real time? If outcome data returns via batch ETL (hours to days), your models are learning slower than they could
- What is your 3-year TCO for the current stack? Include warehouse compute, reverse ETL, messaging platform, identity resolution, and engineering headcount. Compare against an Agentic CDP quote
If you answered “yes” to questions 2–4, you are likely at the Phase 2 inflection point.
Related Articles
- How AI Is Redefining the CDP — How agent-first architecture reshapes what a CDP is and does
- How to Democratize AI Across the Enterprise with a CDP — Making AI accessible to every team through unified data
- Managing Data for AI: Role of the CDP — Research on how CDPs solve AI data management challenges
- Why Every Customer-Facing AI Agent Needs a CDP — How CDPs provide the data foundation for AI agent success
FAQ
Can a cloud data warehouse replace a CDP for customer 360?
Partially — a cloud data warehouse can build the analytical layer of a customer 360 but cannot replace the operational layer. Warehouses excel at unifying data, running batch analytics, and training ML models. CDPs excel at real-time profile serving, native messaging, and closed-loop AI learning. For organizations that only need historical analysis and batch predictions, a warehouse may be sufficient. For organizations that need to act on customer data in real time and learn from outcomes, a CDP provides capabilities the warehouse architecturally cannot.
What is the difference between a CDW-based customer 360 and an Agentic CDP?
A CDW-based customer 360 answers “who is this customer and what might they do?” An Agentic CDP answers “what should we do right now?” and learns from the result. The warehouse-based 360 unifies profiles and enables batch analysis. The Agentic CDP adds real-time identity stitching, native messaging (email, SMS, push), AI decisioning, and closed feedback loops — turning the profile from a reference document into an operational engine that AI agents use autonomously.
How do I know when to add a CDP to my cloud data warehouse?
Add a CDP when your use cases shift from analysis to action. Three signals indicate the inflection point: (1) marketing requests real-time triggered campaigns (cart abandonment, welcome series) that batch sync cannot support, (2) your CISO raises concerns about PII duplicated across 5+ vendor systems via reverse ETL, or (3) AI initiatives require closed feedback loops where models learn from outcomes in seconds, not hours. Most mid-to-large organizations reach this point within 12–18 months of building a warehouse-based customer 360.
