A composable CDP is an approach to building customer data platform capabilities by assembling modular, best-of-breed components — each handling a different stage of the Customer Intelligence Loop — rather than deploying a single, bundled platform. Most composable CDPs are warehouse-native, meaning they leverage your existing cloud data warehouse (such as Snowflake, BigQuery, or Databricks) as the foundation and add specialized tools for identity resolution, segmentation, and data activation.
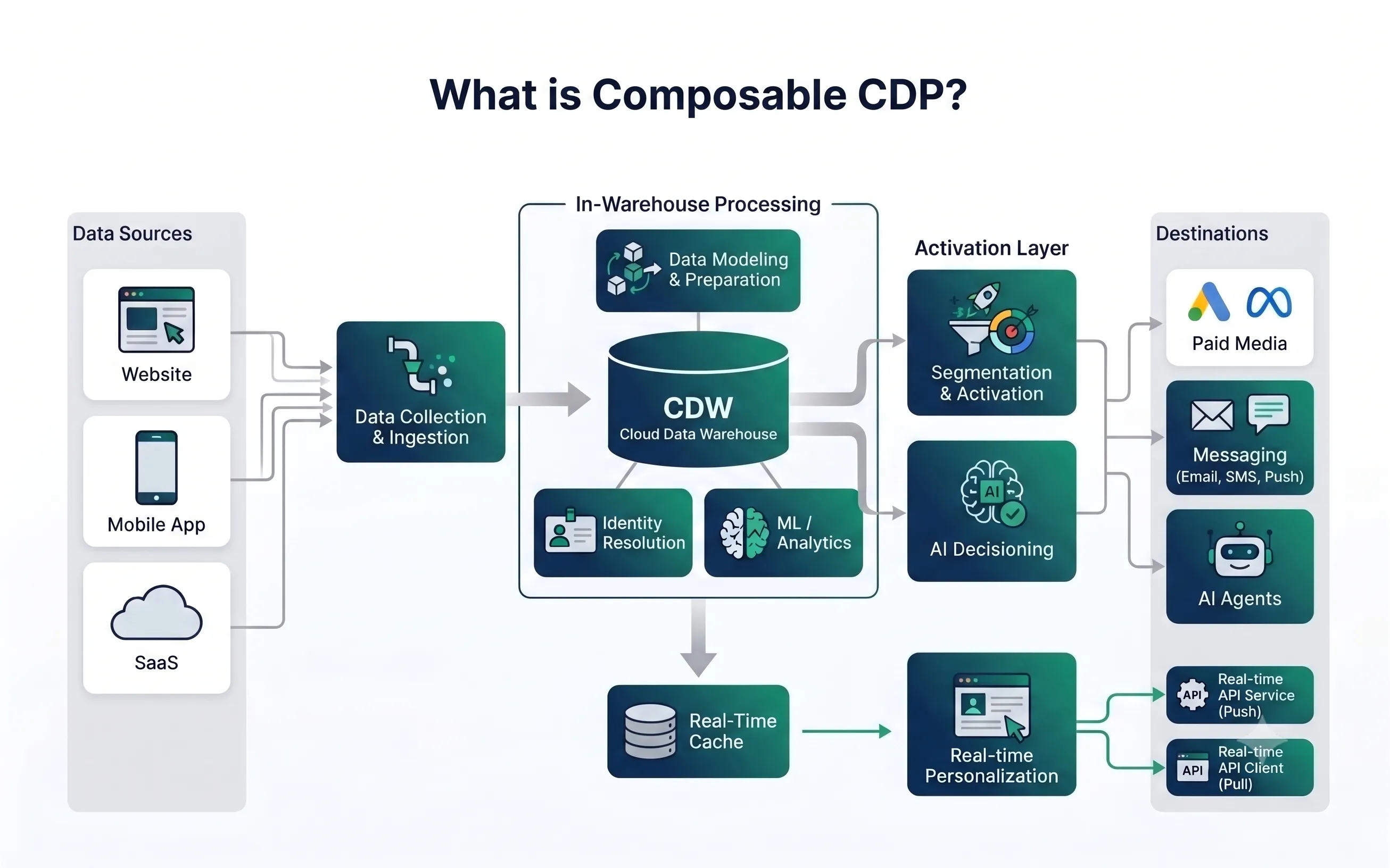
Composable CDP architecture. Data sources feed a cloud data warehouse that handles identity resolution, data modeling, and ML — then an activation layer segments audiences and routes them to paid media, messaging platforms, and AI agents. A real-time cache enables in-session personalization via API.
Rather than consolidating all customer data into a proprietary CDP database, the composable approach keeps unified customer profiles in your warehouse and uses connectors — often via reverse ETL — to sync audiences and attributes to downstream marketing and analytics tools. For a comprehensive overview of CDP fundamentals, see What Is a Customer Data Platform?.
Composable Software: The Underlying Principle
Composable software is an approach to building system infrastructure through independent, interchangeable modules rather than monolithic applications. Core applications are broken into specialized microservices that communicate through APIs, making them easier to scale and faster to develop. Unlike platform architectures—where replaceable modules depend on a shared core system—composable systems allow every component to be swapped without affecting the rest of the stack. A composable CDP applies this same modular philosophy to the customer data technology stack.
What is a Composable CDP?
The term “composable CDP” emerged around 2021 as data teams began questioning whether they needed a traditional, all-in-one CDP when they already had centralized customer data in modern cloud warehouses. The composable philosophy borrows from broader composable software principles: build solutions from interchangeable components instead of monolithic systems.
In a composable CDP architecture, each capability—data ingestion, identity resolution, segmentation, activation—can be fulfilled by a different tool. For example:
- Data ingestion: Connectors and pipelines that collect customer events from websites, apps, CRMs, and other sources into the warehouse
- Transformation & modeling: SQL-based tools that clean, join, and shape raw data into unified customer tables and computed attributes
- Identity resolution: Deterministic or probabilistic matching logic that stitches anonymous and known profiles into a single customer record
- Activation: Reverse ETL tools that sync audiences and attributes from the warehouse to marketing platforms, ad networks, and CRMs
- Orchestration: Schedulers and workflow engines that coordinate pipeline execution, monitor data freshness, and manage dependencies
The warehouse acts as the single source of truth, eliminating data silos and reducing the need to copy customer data into yet another platform. See the Composable CDP Vendors section below for a breakdown of the leading platforms in this space.
How It Works: Mapping Composable Components to the Customer Intelligence Loop
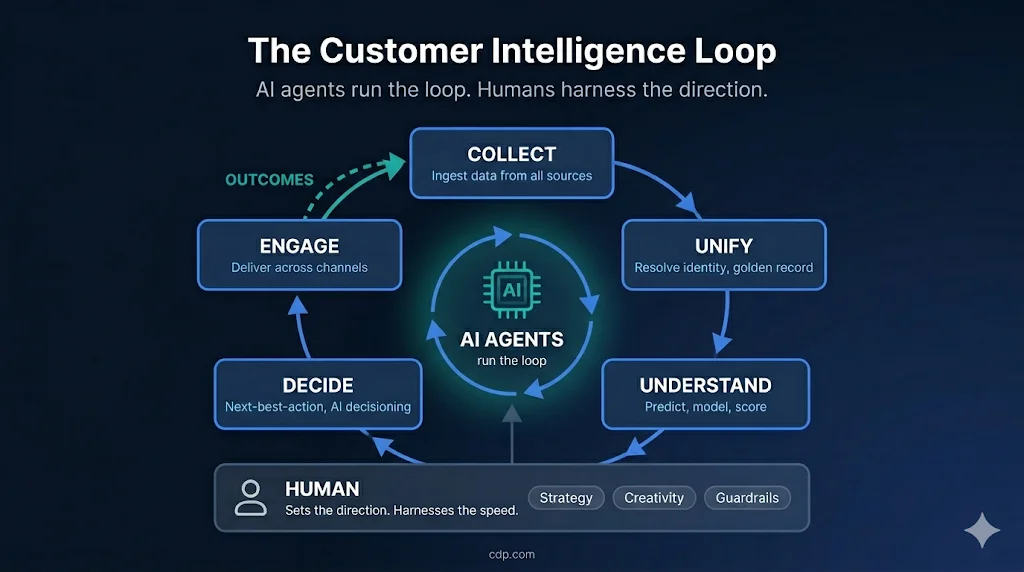
Every CDP — composable or otherwise — must execute the five stages of the Customer Intelligence Loop. In a composable stack, each stage is handled by a separate vendor or tool:
| Loop Stage | Composable Component | What It Does |
|---|---|---|
| COLLECT | Data ingestion pipelines | Batch and streaming connectors pull events from websites, apps, CRMs, and transactional systems into the warehouse |
| UNIFY | Warehouse modeling + identity resolution | SQL and transformation frameworks join raw tables into unified customer profiles with deterministic or probabilistic matching |
| UNDERSTAND | Analytics and ML | BI dashboards, ML notebooks, and custom models surface insights — churn risk, LTV, product affinity |
| DECIDE | Scoring and audience selection | SQL queries and modeling layers score customers and build audience segments for activation |
| ENGAGE | Reverse ETL + external messaging/ad platforms | Sync tools push audiences to email, SMS, push, and ad platforms for campaign execution |
The modularity is real and valuable for engineering control. But notice the architectural consequence: outcomes from ENGAGE (opens, clicks, conversions) must travel back through the entire chain — ESP → reverse ETL → warehouse → dbt rebuild → model retrain — before the system can learn from them.
Warehouse-Native Foundation
Composable CDPs rely on your cloud data warehouse as the storage and compute layer for the COLLECT and UNIFY stages. Customer event streams, transaction records, support tickets, and other data sources are ingested via data integration tools and modeled into unified customer profiles using SQL or transformation frameworks like dbt.
Because the warehouse already stores behavioral, transactional, and demographic data, there’s no need to replicate everything into a separate CDP database. Analysts and engineers can query, join, and enrich customer data using familiar SQL workflows.
Reverse ETL for Activation
Once customer profiles and segments are defined in the warehouse (UNIFY and UNDERSTAND), reverse ETL tools handle ENGAGE by pushing data to operational systems — email platforms (Braze, Iterable), ad networks (Google Ads, Facebook), CRMs (Salesforce, HubSpot), and customer support tools (Zendesk, Intercom).
Reverse ETL essentially inverts the traditional ETL flow: instead of extracting from operational tools into a warehouse, it extracts from the warehouse into operational tools. This enables marketing and customer success teams to activate warehouse-defined audiences without writing code or waiting for engineering support.
Modular Activation and Experimentation
Because components are loosely coupled, teams can swap tools as needs evolve. If a new identity resolution vendor offers better accuracy, you can replace that layer without rebuilding your entire stack. If you want to test a new activation channel, you add a connector without re-architecting your data model. This flexibility is the composable stack’s defining strength — and the source of its structural limitation for AI use cases, where the full cycle must close without crossing vendor boundaries.
Pros and Cons of Composable CDPs
Advantages
Data ownership and portability: Customer data stays in your warehouse, which you control. If you switch activation vendors, your unified profiles remain intact.
Leverage existing investments: If you’ve already built data pipelines, dbt models, and warehouse infrastructure, composable CDPs extend that foundation rather than replacing it.
Flexibility and customization: SQL-based modeling gives teams complete control over how customer attributes are defined, calculated, and enriched. You can incorporate proprietary business logic without waiting for vendor feature releases.
Cost efficiency at entry point: Warehouse-based storage and compute can initially appear more economical than per-profile or platform licensing from Agentic CDPs.
Disadvantages
Pricing can scale up quickly: While composable CDPs often market lower entry costs, total cost of ownership can escalate as data volumes and activation use cases grow. According to G2 reviewer data (2025), users frequently cite unexpected cost increases as connector counts, sync frequencies, and row volumes expand — often approaching or exceeding Agentic CDP pricing at enterprise scale. (Enterprise suites face a parallel cost problem called suite tax — paying for an entire ecosystem to access CDP capabilities.)
Higher complexity: Building a composable stack requires integrating multiple tools, managing dependencies, and ensuring data quality across components. This demands strong data engineering expertise.
Slower time to value: Unlike Agentic CDPs with pre-built capabilities, composable architectures require upfront investment in data modeling, pipeline orchestration, and tool integration.
Limited out-of-box AI: Most composable CDPs rely on separate ML platforms for the UNDERSTAND and DECIDE stages. You won’t get built-in propensity scoring or next-best-action recommendations without additional tooling — and each additional tool is another vendor boundary the feedback cycle must cross.
Maintenance overhead: As your stack grows, so does the operational burden of monitoring the pipeline across vendors — debugging sync failures between DECIDE and ENGAGE, keeping connectors up to date, and ensuring outcome data flows back to COLLECT reliably.
3-Year TCO: Composable vs Agentic
Cost comparisons between composable and agentic CDPs are misleading without modeling total cost of ownership across time. Composable stacks have lower entry costs but scale non-linearly as activation use cases grow. The CDP market is projected to reach $28.2 billion by 2028 at a 39.9% CAGR (MarketsandMarkets, 2023), and much of that growth will be driven by organizations consolidating multi-vendor stacks into unified platforms.
| Cost Category | Composable CDP | Agentic CDP |
|---|---|---|
| Warehouse compute | $50K-300K/year (scales with query volume, dbt rebuilds, ML workloads) | $0-50K/year (optional warehouse connect; managed storage included) |
| Reverse ETL / sync fees | $30K-150K/year (per-row × connector count × sync frequency) | Included (native activation) |
| ESP / messaging platform | $50K-500K/year (separate Braze, Iterable, or similar) | Included (native email, SMS, push) |
| Identity resolution tool | $0-100K/year (separate vendor or warehouse-native SQL) | Included (built-in AI-powered matching) |
| Data engineering headcount | 2-5 FTEs dedicated to pipeline maintenance ($200K-750K/year) | 0.5-1 FTE for CDP administration ($100K-150K/year) |
| Integration maintenance | $25K-100K/year (connector upgrades, debugging, monitoring) | Minimal (pre-built connectors maintained by vendor) |
| 3-year total (10M profiles) | $1.1M-5.7M | $300K-1.2M |
These ranges reflect publicly available pricing tiers and G2 reviewer-reported costs as of 2025, modeled on 10M active profiles with daily syncs to 8 downstream tools at mid-tier ESP contract pricing. Actual costs vary significantly by vendor, data volume, sync frequency, and use case complexity. The key insight is not that composable is “expensive” — it is that composable costs compound multiplicatively (rows × connectors × frequency × tools), while agentic CDP pricing is typically per-profile with activation included.
PII Duplication Across Vendor Boundaries
A composable CDP keeps unified profiles in the warehouse — but activation still requires copying personally identifiable information (PII) to external tools. Every reverse ETL sync that pushes email addresses, phone numbers, or customer attributes to a separate ESP, ad platform, or CRM creates another copy of PII outside your primary data environment. In a typical composable stack, customer PII may exist in three or more systems simultaneously: the warehouse, the reverse ETL tool’s sync cache, and each downstream activation platform.
Each additional copy introduces compliance overhead: separate GDPR Article 28 data processing agreements per vendor, slower deletion-request fulfillment (propagating across 3-5 systems takes days, not minutes), expanded breach surface with independent SOC 2 audit requirements, and data residency complexity when vendors store data in different regions. For a detailed compliance analysis, see CISO’s Guide to CDP Architecture.
Composable CDP Vendors
The composable CDP market includes pure-play reverse ETL tools, warehouse-native audience builders, and hybrid platforms that offer both composable and managed CDP modes.
| Vendor | Type | Key Capability |
|---|---|---|
| ActionIQ | Hybrid CDP | Warehouse-native deployment with managed identity and orchestration (acquired by Uniphore, 2024) |
| Hightouch | Pure-play reverse ETL | Warehouse-native audience builder with 200+ destination connectors |
| Salesforce Data Cloud | Zero-copy (Salesforce ecosystem) | Zero-copy data sharing across Salesforce products and external warehouses |
| Treasure AI | Composable + Complete CDP | Composable Audience Studio for zero-copy federated queries on Snowflake, BigQuery, and Databricks, plus a Complete CDP with real-time profiles, native messaging, and AI decisioning |
Other notable composable CDPs include Census (warehouse-native reverse ETL, acquired by Fivetran in 2025) and RudderStack (open-source event streaming with reverse ETL). For a side-by-side comparison with pricing and feature details, see the composable CDP vendors overview.
When Composable CDPs Make Sense
Composable CDPs are a strong fit when your organization already has a mature cloud data warehouse with well-modeled customer data and a data engineering team that can maintain the multi-vendor pipeline. Specifically, composable works well when:
- Your activation cadence is batch-oriented — daily or weekly audience syncs, periodic reporting — and that speed is sufficient
- You need custom data models or complex identity resolution logic that off-the-shelf matching cannot handle
- You want to avoid per-profile pricing or vendor lock-in
- Your AI/ML needs are limited to batch-trained models (churn prediction, LTV scoring) that tolerate hourly or daily data refreshes
For organizations that need real-time feedback loops, built-in AI decisioning, or sub-second profile access for personalization, an Agentic CDP may be a better fit. An Agentic CDP bundles data collection, identity resolution, AI decisioning, and native messaging into a single platform — allowing AI agents to run the full Customer Intelligence Loop continuously without crossing vendor boundaries. Some Agentic CDPs also support hybrid deployment, connecting to your existing warehouse while adding managed storage for real-time use cases. For a detailed comparison, see Packaged vs Composable CDP.
AI and the Feedback Loop Challenge
As venture capitalist Tomasz Tunguz argues in AI’s Bundling Moment, AI is reversing the SaaS era’s unbundling playbook — AI systems perform best when they can observe entire workflows end-to-end and act on insights in real time. In a composable stack, the Customer Intelligence Loop is split across vendor boundaries: outcomes from ENGAGE (opens, clicks, conversions) must travel back through the ESP, reverse ETL, warehouse rebuild, and model retrain before the system can learn — a round-trip measured in hours, not seconds.
This feedback latency is manageable for batch use cases (weekly audience syncs, periodic reporting) but becomes a structural limitation for real-time AI decisioning and agentic marketing. Organizations weighing this trade-off should evaluate how fast they need the loop to close and whether a hybrid deployment or Agentic CDP better fits their real-time requirements. For a detailed analysis, see Packaged vs Composable CDP and How to Evaluate a CDP in the AI Era.
FAQ
What is the difference between a composable CDP and a data warehouse?
A data warehouse is infrastructure for storing and querying data. A composable CDP is an architecture that uses your data warehouse as the foundation, then adds specialized tools for identity resolution, segmentation, and activation. The warehouse provides the “what” (unified customer data), while the composable CDP tools provide the “how” (turning that data into actionable customer experiences).
Can small companies use composable CDPs, or are they only for enterprises?
Composable CDPs generally require more technical expertise and infrastructure than integrated CDPs, making them better suited for mid-market and enterprise organizations with dedicated data teams. However, startups with strong engineering resources and existing warehouse investments can adopt composable approaches—especially if they already use modern data stacks (Fivetran, dbt, Snowflake) and want to avoid the cost and complexity of adding another proprietary platform.
Can composable CDPs support agentic AI and real-time marketing?
Composable CDPs handle triggered real-time messages (abandoned cart, order confirmation) effectively, but struggle with continuously-learning AI agents. The distinction matters: sending a triggered message based on a pre-defined rule works fine in composable stacks. The structural limitation is continuous learning — when AI agents need to act, observe the outcome, and improve the next decision in seconds. In composable architectures, outcomes must traverse reverse ETL back to the warehouse, then through dbt rebuilds and model retraining, before the system learns — a round-trip measured in hours, not seconds. For use cases requiring closed-loop learning, Agentic CDPs with built-in messaging and AI decisioning keep the entire cycle within a single platform boundary.
Further Reading: How to Evaluate a CDP in the AI Era: 10 Questions Every Buyer Should Ask
How does reverse ETL differ from packaged CDP activation?
Packaged CDPs store customer profiles in their own database and activate them via pre-built integrations to marketing tools. Reverse ETL flips this model: customer profiles live in your warehouse, and reverse ETL connectors sync segments and attributes to downstream tools on demand. This keeps your warehouse as the source of truth and eliminates the need to duplicate customer data into yet another system. The end result—personalized campaigns, targeted ads, enriched CRM records—is similar, but the underlying data flow is fundamentally different.
What is composable CDP architecture?
Composable CDP architecture uses your cloud data warehouse as the foundation and layers modular tools on top for each CDP function. The typical stack maps to the five stages of the Customer Intelligence Loop: data ingestion tools (Fivetran, Airbyte) handle COLLECT, SQL and dbt handle UNIFY and UNDERSTAND, reverse ETL tools handle DECIDE/ENGAGE by syncing audiences to downstream platforms. Each component can be swapped independently, but every vendor boundary introduces integration complexity and latency. See the Loop mapping table above for a detailed component breakdown.
Is Snowflake or BigQuery a composable CDP?
No — Snowflake and BigQuery are data warehouses, not CDPs, but they serve as the foundation layer for composable CDP architectures. A warehouse stores and queries customer data but lacks native identity resolution, audience segmentation, and marketing activation. Building a composable CDP on top requires adding specialized tools for each capability. For detailed assessments, see Is Snowflake a CDP? and Is Databricks a CDP?.
Related Terms
- Data Warehouse — The storage layer that composable CDPs build upon
- Data Governance — Policies for managing data quality across multi-vendor stacks
- Customer Data Platform — The broader category composable CDPs belong to
- Real-Time CDP — Streaming architecture that composable stacks struggle to replicate
- Data Lakehouse — Alternative foundation layer some composable stacks use
- Customer Intelligence Loop — The five-stage cycle composable stacks split across vendors
